在linux系統上開發C/C++,我們幾乎都會利用gcc來將程式碼轉成目的檔再作執行,在以前,我總是不管這些細節,認為這些鎖事交給compiler跟OS去擔心就好, 直到工作碰到了,翻閱資料才發現以前對程式的了解真的是相當的粗淺,甚至不堪一擊,以下就稍微細論linux目的檔的內容。
在linux中,這些目的檔的格式為ELF(Executable Linkable Format),與Windows下的PE(Portable Executable)其實系出同源,都是延伸自COFF(Common object file format),在此處我僅探討ELF。 不討論太多靜態連結與動態連結的細節,你可以把他當作一個查詢用的資料。
1. 目的檔的內容:
目的檔的內容我們可以很直覺的猜測其中必定包含有機器語言程式碼與資料,但目的檔只包含這些東西嗎?其實不只,目的檔還包含了連結資訊、字串表、符號表…等 ,為了方便管理,ELF將其分為一個個區段(section)來作儲存,以下先列出常見的區段。
1. 常見的區段
| 常見的區段名稱 | 說明 |
|---|---|
| .text | 程式碼區段,存放可執行之程式碼 |
| .data | 已初始化之資料(初始值不為0,否則會放入.bss之中),資料含有全域變數與區域靜態變數 |
| .bss | 未初始化之資料,資料含有全域變數與區域靜態變數,儲存在硬體不佔空間 |
| .rodata | 唯讀資料區段 |
| .dynamic | 動態連結資訊 |
| .dynstr | 動態連結時的字串表 |
| .dynsym | 動態連結時的符號表 |
| .got | 動態連結時的全域入口表 |
| .plt | 動態連結時的跳轉表 |
| .interp | 動態連結器的路徑 |
| .ctors | 保存c++的全域建構函式的指標 |
| .dtors | 保存c++的全域解構函式的指標 |
| .hash | 符號表的雜湊表,主要用以加快速度 |
| .init | 程式執行前的初始化程式碼,在main之前執行 |
| .fini | 程式退出時所執行的程式碼,在main之後執行 |
| .rel.(name) | 重定表,用來重定(name)這個區段的內容 |
| .shstrtab | section header string table,段頭字串表 |
| .strtab | string table,字串表 |
| .symtab | symbol table,符號表 |
| .debug | 除錯資訊 |
| .line | 包含除錯時使用的行號資訊 |
| .comment | 包含編譯器的版本資訊 |
| .note | 額外程式區段,提供編譯器、連結器或作業系統廠商存放資料 |
2. 各區段的詳細介紹:
1. ELF檔頭
這是每個ELF最重要的部份,系統會由他來解析ELF檔案,其內可細分為:
- ELF魔數(ELF magic):可用來告訴系統為elf檔,是32位元還是64位元,是little endian還是big endian,是ELF的那個版本(基本上都是第一版(1.2),沒在更新了)。
- 資料類型(Type):可分為可重定檔、可執行檔、共用目的檔。
- 機器類型(Machine):描述其在那個機器平台上執行。
- 程式入口位址(Entry point address):紀錄當作業系統載入完程式,要從那個虛擬位置開始執行
- 段頭檔開頭偏移(Start of section headers): 檔案在ELF中的位置
- 程式標頭開頭偏移(Start of program headers):
- ELF檔頭大小(Size of this header):這個標頭檔的大小
- 程式標頭的大小(Size of program headers):
- 程式標頭描述項的數量(Number of program headers):
- 段頭檔描述項大小(Size of section headers):段頭檔內每個段的標頭有多大
- 段頭檔描述項的大小(Number of section headers):段頭檔內有幾個段的標頭檔
- 段頭表字串表索引(Section header string table index):為一個整數用來當作index去字串表取對應的字串
2. 段頭表
段頭(section header)用描述每個段特性,而段頭表則是這些段頭的集合(可以視為是段頭的陣列),每一段段頭可以在細分為:
- 區段名稱(Section Name):事實上是個整數用來當作index,從.shstrtab取字串出來
- 區段類型(Section Type):與區段旗標一起來決定區段的類型,用來決定是程式區段、符號表、字串表、重定表、雜湊表、動態連結資訊、提示性資訊、重定資訊、動態連結的符號表或告知該區段不含內容。
- 區段旗標位元(Section Flag):旗標則是用來決定是否可寫可執行或需要分配空間。
- 區段虛擬位置(Section Address):如果該區段可以載入記憶體,則該區段在虛擬記憶體的位置
- 區段偏移(Section Offset):如果該區段存於檔案中,此變數代表此區段在檔案的偏移
- 區段長度(Section Size):區段長度
- 區段連結與區段資訊(Section Link and Section Information):如果是區段的類型是與連結相關的,這個兩個參數才會有意義,詳細意義可見“程式設計師的自我修養:連結、載入、程式庫”第三章
- 區段位置對齊(Section Address Alignment):用來指示區段內的位置該針對$2^n$次方對齊
- 區段項目長度(Section Entry Size):有些區段包含了一些固定大小的項目,比如說符號表,因為每個符號佔的大小都一樣,故在這邊儲存每各項目的長度
3. 符號表
每個函數及變數在目的檔中,會被視為符號(symbol),當作連結時的介面,而函數與變數的名稱就是符號名稱,每一個目的檔都會有一個對應的符號表,表內紀錄了所用到的所有符號,每個符號都有個對應的值, 稱為符號值(symbol value),裡面儲存變數與函數的虛擬位址,當然,尚未連結之前,有些值是無效的,直接使用跳至那些位置並無法正確執行。
我們可以將定義在符號表的符號簡單的分為幾類:
- 定義在本目的檔的全域符號,可以被其他目的檔引用
- 在本目的檔引用的外部全域符號,一般稱為(global symbol)
- 區段名稱,這類符號由編譯器產生,他的值就是這個區段的起始位置(ex. .text, .data)
- 區段符號,只在編譯單元可見,連結過程沒有用處。
- 行號資訊,也非必要資訊。
舉例來說: 如果今天有一個C程式叫做test.c,我們可以利用nm來觀察其內部的符號情形。
int global_var_0 = 0;
int global_var_1 = 1;
int main(){
extern int extenal_global_var;
int local_var_1 = 1;
static int static_local_var = 2;
printf("hello world %d",extenal_global_var);
return 0;
}
$ gcc -c test.c
$ nm test.o
U extenal_global_var
U _GLOBAL_OFFSET_TABLE_
0000000000000000 B global_var_0
0000000000000000 D global_var_1
0000000000000000 T main
U printf
0000000000000004 d static_local_var.1798
我們可以看到他裡面的符號有extenal_global_var,global_var_0,global_var_1,main,printf,static_local_var.1797和got(_GLOBAL_OFFSET_TABLE_), 其中B代表位於.bss,T代表位於.text,D代表其位於.data,U代表undefined,根據常見的區段內的介紹,我們大致可以了解 global_var_1 ,static_local_var.1798和 main的情形。
但仍然有幾個問題需要被解決:
- 為什麼 printf 是U呢? 這是因為 printf 其實是定義在 C語言標準函式庫內的函式,因為我們尚未將它連結起來,故編譯的過程其實不清楚他到底是怎麼樣的符號,extenal_global_var也是類似的情形。
- 為什麼global_var_0是在.bss而不是.data? 那是因為編譯器為了在儲存時節省儲存資源,會將初始值為0的全域變數一樣放入.bss之中,因為在.bss內的變數(沒初始值的全域變數)在初始化時都會給與0這個值,且在實際儲存的時候,這個區段的資料並不真正儲存,而是這部份的資料是執行時期生出來的,這可以有效的節省儲存資源。
- GOT是什麼呢? GOT則是一個比較有趣的table,這部份的解釋我們留到未來再做探討。
4. 重定表
在連結各個目的檔之前,目的檔內有些部份的位址其實只是暫時的,可能只是個暫時的虛擬位址或是單純是0…,這些位址在連結的過程中必須要透過連結器,來作重定, 讓它們連結到正確的位址,確保實行的過程中,可以有效地執行。
舉例來說,如果在程式碼中有呼叫其他目的檔中定義的程式碼,或是呼叫其他目的檔中的全域變數,在編出elf檔時就會在插入rel.text(程式碼區塊的重定表)或是rel.data(初始化全域變數區塊的重定表)。
詳細的重定過程在這邊先行略過,留到之後再作補充。
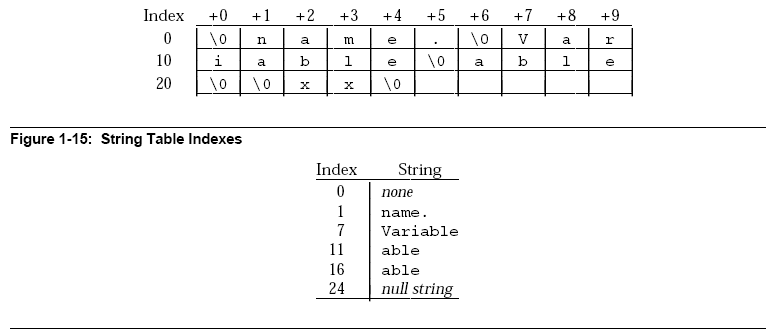
5. 字串表
ELF檔用到很多字串(像是區段名、變數名、字串常數等),ELF把他集結起來構成字串表,要使用字串時,則透過一個整數來取其開頭的位置, 字串表可以細分為字串表(String Table)與段頭字串表(Section Header String Table)。 段頭字串表儲存每個段頭的名字,而字串表則是儲存段頭名以外的字串。
3. 分段的好處
分段的好處有以下幾點:
- 方便作讀寫執行(rwx)的權限管理
- 提高cache hit的機會(可從data跟instruction分開得知)
- 共同的部份只須在記憶體中放一塊,可以大量節省實體記憶體的空間
4. 區段運作情形
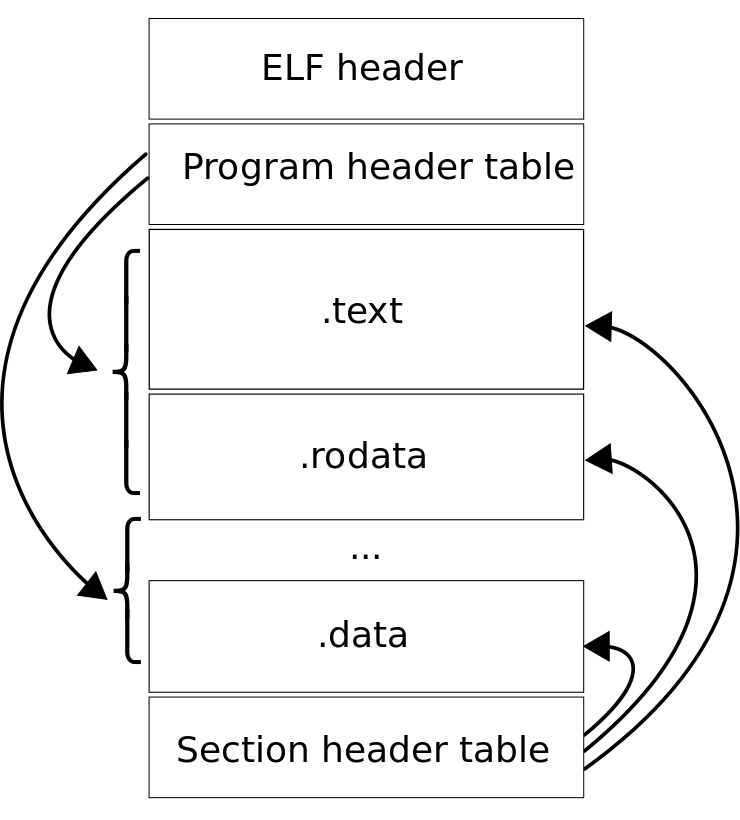
可以由上圖先得知ELF大概的長相,每一個ELF檔最重要的就是ELF Header,ELF Header告訴連結器或作業系統這個執行檔的一些資訊, 透過ELF Header,可以在得到其他的section header table的資訊,section header table描述了每個section 的特性與其進入的位置
4. 各區段分析
參考資料:
俞甲子、石凡、潘愛民,”程式設計師的自我修養:連結、載入、程式庫”,碁峰, 第三章